- CTO AI Insights
- Posts
- HuatuoGPT-o1: Revolutionizing Medical Reasoning with Advanced AI
HuatuoGPT-o1: Revolutionizing Medical Reasoning with Advanced AI
HuatuoGPT-o1 is a groundbreaking medical language model designed to enhance reasoning capabilities in the healthcare domain. Developed by researchers from The Chinese University of Hong Kong and Shenzhen Research Institute of Big Data, this innovative model aims to address the complex challenges of medical reasoning[1].
Chris Jones
December 30, 2024
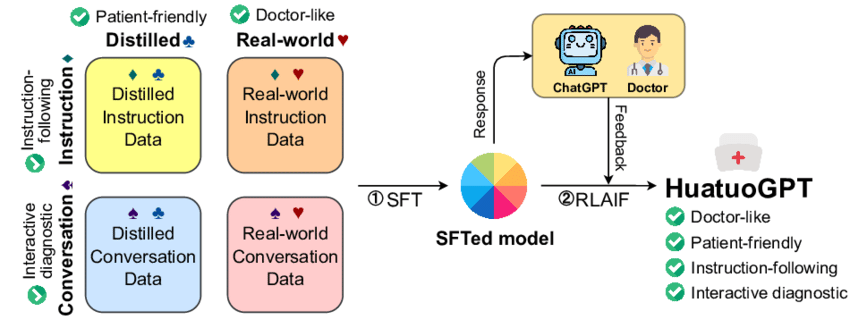

Key Features and Capabilities
Advanced Reasoning: HuatuoGPT-o1 employs a unique “thinks-before-it-answers” approach, generating a complex thought process before providing a final response[2]. This allows for more thorough and accurate medical reasoning.
Two-Stage Learning Process:
1. The model develops complex reasoning skills through feedback-driven iterations.
2. It then refines these skills using reinforcement learning (RL)[1].
Verifiable Medical Problems: The model is trained on a dataset of 40,000 carefully curated and verifiable medical problems, enabling it to align its solutions with verifiable outcomes[1].
Multiple Versions: HuatuoGPT-o1 is available in various sizes and language capabilities:
• 8B and 70B parameter versions based on LLaMA-3.1 (English only)
• 7B and 72B parameter versions based on Qwen2.5 (English and Chinese)[2][3]
Performance and Benchmarks
HuatuoGPT-o1 has demonstrated impressive results in various benchmarks:
• The 8-billion parameter version showed an 8.5-point improvement over its baseline.
• The 70-billion parameter version outperformed top medical-specific LLMs on datasets like MedQA and PubMedQA[1].
These results highlight the model’s robust reasoning capabilities across both traditional and complex medical datasets.
Usage and Implementation
Researchers and developers can easily integrate HuatuoGPT-o1 into their projects using popular machine learning libraries. The model can be deployed using tools like vllm or Sglang, or used for direct inference[2][3]. The output format typically includes a “Thinking” section detailing the reasoning process, followed by a “Final Response” section with the conclusion.
Implications for Healthcare
HuatuoGPT-o1 represents a significant advancement in medical AI, potentially improving decision-making processes in healthcare. Its ability to generate detailed chains of thought and refine answers iteratively could enhance diagnostic accuracy, treatment planning, and medical research.
This innovative model demonstrates the potential of applying advanced AI techniques to specialized domains like medicine, paving the way for more accurate and reliable AI-assisted healthcare solutions.
Citations:
HuatuoGPT-o1-7B: https://huggingface.co/FreedomIntelligence/HuatuoGPT-o1-7B
HuatuoGPT-o1-72B: https://huggingface.co/FreedomIntelligence/HuatuoGPT-o1-72B
Can HuatuoGPT-o1 be used for real-time medical consultations
While HuatuoGPT-o1 demonstrates advanced medical reasoning capabilities, it is not currently designed or approved for real-time medical consultations. There are several important factors to consider:
1. Research tool: HuatuoGPT-o1 is primarily a research model developed to enhance medical reasoning in language models. It was trained on curated medical problems to improve complex reasoning skills[2].
2. Lack of real-time interaction: The model is not designed for interactive, real-time conversations like those required in medical consultations. It processes pre-formulated medical problems rather than engaging in dynamic dialogue[2].
3. Regulatory considerations: Using AI models for actual medical consultations would require extensive clinical validation and regulatory approval, which HuatuoGPT-o1 has not undergone[8].
4. Supervised use: Even if adapted for consultations, AI models in healthcare typically require supervision by medical professionals to ensure patient safety and quality of care[3].
5. Ethical and legal implications: Direct patient consultations using AI raise significant ethical and legal questions that would need to be addressed before implementation[8].
While HuatuoGPT-o1 shows promise in advancing medical AI, it is currently best suited as a tool to assist healthcare professionals in research, education, and decision support rather than for direct patient consultations. Any application in clinical settings would require further development, validation, and regulatory approval.
Citations: [1] https://openreview.net/forum?id=KRQADH68fG
How does the reinforcement learning component improve HuatuoGPT-o1's performance
The reinforcement learning (RL) component plays a crucial role in improving HuatuoGPT-o1’s performance in medical complex reasoning. Here’s how RL enhances the model’s capabilities:
Two-Stage Approach
HuatuoGPT-o1 employs a two-stage approach to advance medical complex reasoning:
1. Learning Complex Reasoning: The model first develops complex reasoning skills through feedback-driven iterations.
2. Enhancing Complex Reasoning with RL: After acquiring initial reasoning skills, reinforcement learning further refines this ability[2].
RL Implementation
The RL component in HuatuoGPT-o1 works as follows:
1. Verifier-based rewards: The model receives sparse rewards provided by a medical verifier, which guides the self-improvement process[2].
2. PPO algorithm: The Proximal Policy Optimization (PPO) algorithm is used to implement the RL training[2].
3. Iterative refinement: Through RL, the model learns to recognize and correct its mistakes, break down complex steps, and try different approaches when needed[2].
Performance Improvements
The inclusion of RL in HuatuoGPT-o1’s training process leads to significant performance enhancements:
1. Benchmark improvements: The 8B parameter version of HuatuoGPT-o1 showed an 8.5-point improvement on medical benchmarks after incorporating RL[2].
2. Outperforming baselines: The 70B parameter version outperformed other open-source general and medical-specific LLMs across multiple medical benchmarks[2].
3. Enhanced problem-solving: Experiments revealed that complex reasoning enhanced by RL improves medical problem-solving compared to standard or non-Chain-of-Thought methods[2].
Continuous Learning
The RL component enables HuatuoGPT-o1 to continuously improve its performance:
1. Adaptive learning: The model can adapt its strategies based on feedback, allowing it to refine its reasoning process over time[2].
2. Scalability: The performance of the model consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute)[7].
By incorporating reinforcement learning, HuatuoGPT-o1 can generate more accurate and refined responses to complex medical queries, ultimately leading to improved performance across various medical reasoning tasks.
Citations: [1] https://openai.com/index/learning-to-reason-with-llms/ [2] https://arxiv.org/pdf/2412.18925.pdf [3] https://pmc.ncbi.nlm.nih.gov/articles/PMC9924115/ [4] https://openreview.net/forum?id=KRQADH68fG [5] https://arxiv.org/abs/2412.18925 [6] https://www.nature.com/articles/s41746-024-01316-0 [7] https://www.reddit.com/r/mlscaling/comments/1ff7v41/introducing_openai_o1/ [8] https://pmc.ncbi.nlm.nih.gov/articles/PMC10627901/ [9] https://pubmed.ncbi.nlm.nih.gov/33436272/ [10] https://creators.spotify.com/pod/show/arxiv-papers/episodes/QA-HuatuoGPT-o1–Towards-Medical-Complex-Reasoning-with-LLMs-e2ssmto
Reply